

前回の記事『AIで多言語をトランスミュート!学習効率を最大化する実装設計』にて、Velocity Englishをさらに進化させるためのプロダクト再定義を行いました。
今回からはその実装フェーズ第1弾として、「思考を止めない言語スイッチ」の実装――状態管理編を始めていきます。
従来の翻訳アプリは「入力前に言語を選ぶ」のが一般的。
しかし、それでは直感的な思考が途切れてしまいます。日本語を入力した後、ボタン一つで色を変えるように言語を切り替えられれば、ユーザーは「翻訳設定」にリソースを割くことなく、純粋なアウトプットに集中できるようになる。
これを実現する鍵が、Streamlitの st.session_state 。
これは、スクリプトが再実行されても「ブラウザのタブが閉じられるまでデータを保持し続けてくれる辞書型の箱」のようなものです。
Streamlitは操作のたびにコードが上から下まで再実行される性質を持っています。そのため、普通の変数では実行のたびにデータが初期化(破棄)されてしまい、「入力した文字が消える」「切り替えるたびにAPIを叩き直す」といった、UX的にもAPIコスト的にも致命的な問題が発生します。
今回は st.session_state を使い倒して、この挙動を支える「土台」を作っていきます。
2. 【設計思想】なぜ「後出しスイッチ」なのか?
ただ翻訳するだけなら、世の中には優れたツールが山ほどあります。それでも俺が「入力後に言語を切り替える」という挙動にこだわったのには、エンジニアとしての、そして一人の学習者としての明確な理由が3つある。
① 直感(思考)を邪魔しない
一般的な学習ツールは、まず「何語を話すか」をユーザーに選ばせる。だが、人間の思考はもっと自由で、とりとめがないものだ。一つに対して取り組む集中力が無いと言えばそれまでだが、 「今の独り言、スペイン語ならどう響く? いや、フランス語の方がしっくりくるかも」 そんな風に、思考の結果を見てから色を変えるように言語を切り替えたい。 最初に言語を固定してしまうという「手続き」を排除することで、脳のリソースをすべて「言葉を生み出すこと」に集中させる設計にした。
【設計のポイント1:直感(思考)を邪魔しない】
- 現状: 多くのツールは、まず「これから何語で話すか」を先に決めさせる。
- 思想: 「今の独り言、スペイン語ならどう響く?」という事後の好奇心を最大化したい。
- 効果: 言語選択という「手続き」を思考の後に持ってくることで、学習の心理的ハードルを下げる。
② 「能動的選択」を記憶のトリガーにする
AIは入力された音声・テキストが何語かを自動判別する機能を実装することは出来る。しかし、便利すぎるものはかえって記憶に残りにくい。 あえて[ES]や[FR]といったボタンをユーザーにポチッと押させる。この「自分で言語を選んだ」という能動的なアクションを取った方がが、脳に対して「これは今から覚えるべき重要な情報だ」と認識させるスイッチになる。 「楽をさせる」のではなく「記憶にフックをかける」ために、あえての手動スイッチとする。
【設計のポイント2:能動的選択を記憶のトリガーにする】
- 現状: AIによる自動翻訳は便利だが、受け身になりやすく記憶に残りにくい。
- 思想: ユーザーが自分で「[ES]」ボタンをポチッと押す。この「自分で選んだ」という小さな能動的アクションを記憶のスイッチにする。
- 効果: 「楽をさせる」のではなく「脳にフックをかける」ことで、定着率を向上させる。
③ 構造(Core + Meat)を多言語で使い回す
一度日本語を「構造」として解剖してしまえば、その骨組み(Core)は世界中の言語で共通して使える。 「後出し」で言語を切り替えることで、同じ骨組みを維持したまま、皮(言語)だけが次々と貼り替わっていく(トランスミュートする)体験ができる。これにより、「言語ごとのリズムや音の違い」だけを純粋に比較・抽出することが可能になるんだ。
【設計のポイント3:解剖結果(Core + Meat)の再利用】
- 現状: 言語を変えるたびに、一から翻訳し直すのが一般的。
- 思想: 一度日本語を「構造」として解剖したら、その骨組み(Core)は共通。皮(言語)だけを貼り替える(トランスミュートする)体験を作る。
- 効果: 言語ごとの「リズムの違い」だけを純粋に比較・抽出することが可能になる。
3. 実装の核心:st.session_state による状態管理
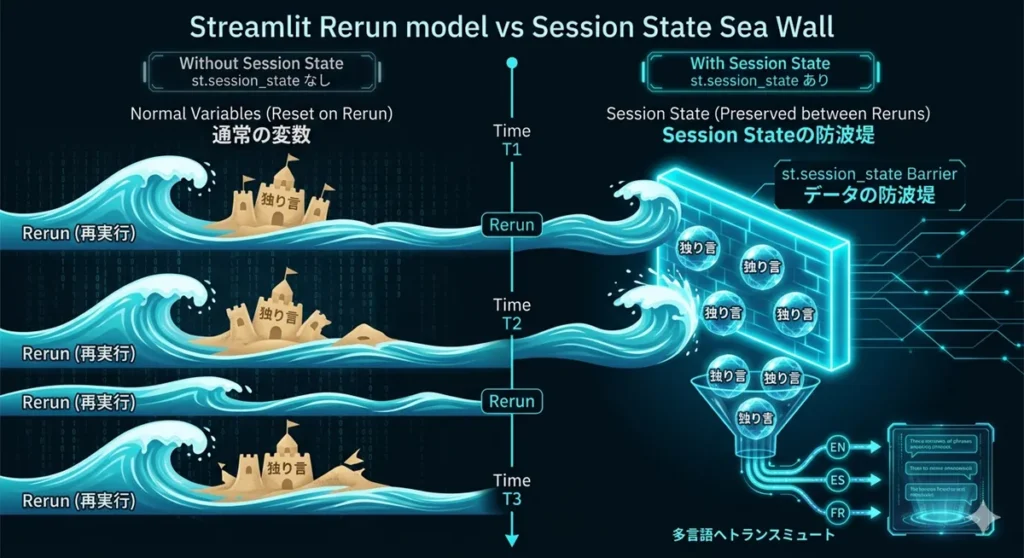
Streamlitで「思考を止めないUX」を実現するための、具体的なコード戦略を紐解いていく。
【実装のポイント1:データの「定位置」を決める初期化】
Streamlitは操作のたびにコードが最初から走り直す。そのため、まずは「箱(session_state)」の中に必要なスペースを確保する初期化処理が必要となる。
Python
import streamlit as st
# セッション状態の初期化
if "app_state" not in st.session_state:
st.session_state.app_state = {
"user_input": "", # 入力された日本語
"results": {}, # 各言語の解析データ(EN, ES, FRなど)
"current_lang": "JP" # 現在表示している言語モード
}
if "key" not in st.session_state: というガードを置くことで、再実行されても既存のデータがリセットされず、未定義エラーも防ぐことができる。
実装順序としては、まず『器(Session State)』を完璧に定義し、その後に『ロジック(引数の追加など)』を弄るのが鉄則。ここを同時に変えようとすると、バックエンドが新しい引数を受け取れずに一時的なエラー(TypeError)を吐き続け、開発のテンポを損なうことになるからだ。
【実装のポイント2:状態を切り替えるコールバック関数】
ボタンを押した瞬間に「表示言語」を切り替えるには、ボタンの on_click プロパティを活用する。
Python
def switch_lang(lang_code):
# 表示する言語フラグを更新するだけの、極めて軽量な処理
st.session_state.app_state["current_lang"] = lang_code
# UI部分:各言語のボタン
cols = st.columns(4)
languages = ["JP", "EN", "ES", "FR"]
for i, lang in enumerate(languages):
cols[i].button(lang, on_click=switch_lang, args=(lang,))
ここで重要なのは、**「ボタンを押してもAPIを叩かない」**という設計だ。current_lang というフラグを書き換えるだけで、表示ロジック(後述)にバトンを渡す。
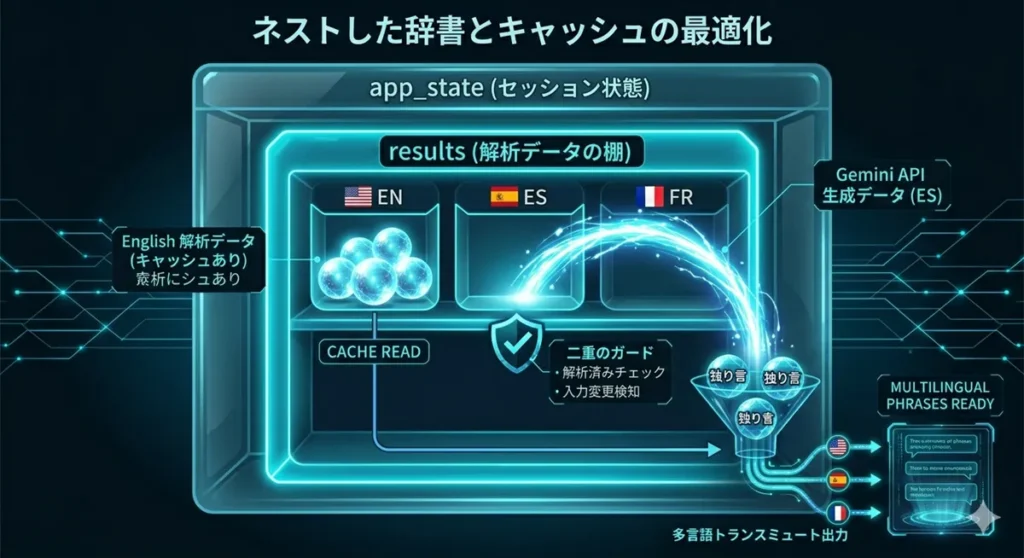
【実装のポイント3:キャッシュ(Results)の再利用】
一度AIが生成したデータは results 辞書に保存しておく。これにより、言語を往復しても再生成(APIコスト発生)が起きない「爆速の切り替え」が可能になる。
Python
target = st.session_state.app_state["current_lang"]
if target == "JP":
st.write(st.session_state.app_state["user_input"])
elif target in st.session_state.app_state["results"]:
# すでに解析済みなら、保存されたデータ(キャッシュ)を表示
display_result(st.session_state.app_state["results"][target])
else:
# データがなければここで初めてAIを呼び出す(次回へ続く!)
pass
この「状態の分離」こそが、この記事で言いたかった「色を変えるように言語を切り替える」体験の技術となる。
4. 泥臭い検討:キャッシュ vs セッション
「爆速のUX」を取るか「APIコストの削減」を取るか。どちらも捨てがたい選択肢。
これは二律違反するテーマで、どちらか一方しか選び取ることは出来ない。
だが、どちらも工夫次第で選び取ることが出来る。そのために必要なのが、データの扱い。つまりはデータの保存場所の検討だ。
データをキャッシュとして保存するか、データをブラウザのセッションで保有するか。
今回は後者を選択する。
【検討のポイント1:なぜ st.cache_data ではなく st.session_state なのか?】
Streamlitには st.cache_data という強力なキャッシュ機能がある。しかし、今回はあえて st.session_state をメインに据えた。
st.cache_data: サーバー側に保存され、全ユーザーで共有される。st.session_state: ブラウザのセッションごとに独立している。
ユーザーが入力する日本語は千差万別だ。誰かが入力した「こんにちは」の解析結果をサーバー全体でキャッシュしても、他のユーザーに再利用される確率は極めて低い。それどころか、プライバシーの観点からも「ユーザー個別の箱」であるセッション管理の方が安全だと判断した。
【検討のポイント2:コストを守る「二重のガード」】
API(Gemini)を叩くのは、お金がかかる「贅沢な処理」だ。一般的にはChatGPTやGeminiは無料で使えているからコストを払う必要なんてないだろ?と思うかもしれないが、本来はコストがかかっている。
そこで、無駄なリクエストを防ぐために以下のロジックを組む
- 解析済みチェック:
if target in st.session_state.results:で、一度生成した言語は二度とAIに投げない。 - 入力変更の検知: もし元の日本語が書き換えられたら、古いキャッシュ(results)をすべてクリアする。
【検討のポイント3:ライフサイクルの設計】
このデータはいつまで保持すべきか? 「タブを閉じたら消えていい。でも、タブが開いている間は、英語からスペイン語に切り替え、また英語に戻った時に一瞬で表示されなければならない。」 この「短期的だが絶対的な保持」という要件に、st.session_state のライフサイクルが完璧に合致している。
技術的には全言語を同時に生成する『並列処理』も可能ですが、今回はあえて見送りました。YAGNI(You Ain’t Gonna Need It)の原則に基づき、ユーザーが本当に必要とした時だけリソース(APIコスト)を使う設計の方が、プロダクトとして誠実で堅牢だからです。
【Tips:関数の「後方互換性」を保つ設計】 今回、generate_sentence 関数を多言語対応に拡張しましたが、ここで一つ工夫したのがデフォルト引数の活用です。
Python
def generate_sentence(japanese_input: str, lang="EN"):
# langが指定されなければ、自動的に英語(EN)として処理する
プログラムを大規模に改修する際、いきなり関数の形を変えてしまうと、修正が追いついていない他の箇所でエラーが多発します。あえて lang="EN" とデフォルト値を設定しておくことで、古い呼び出し箇所を壊すことなく、安全かつ段階的に機能を拡張できる。こうした「壊さない工夫」が、スピード感のある開発には不可欠です。
. まとめと次回の予告
第1回では、st.session_state を活用した状態管理の実装について解説しました。 「入力した後に言語を選ぶ」という、一見シンプルですが、Streamlitの再実行モデル(Rerun)を逆手に取ったこの設計こそが、Velocity Englishの「思考を止めない体験」の正体です。
- 初期化の徹底: データの「定位置」を確保し、エラーを防ぐ。
- コールバックの活用: UI操作と重い処理を切り離し、爆速のレスポンスを実現する。
- セッションの最適化: ユーザー個別の「箱」でデータを守り、APIコストとプライバシーを両立させる。
「どう動かすか」の前に「どうあるべきか」を設計する。この泥臭い土台作りが、プロダクトの堅牢さを決めます。
【次回の予告:多言語をハックする「知能」の設計】
土台は整いました。しかし、この「箱」の中に詰め込む多言語の解析データは、一体どうやって生成しているのか?
英語、スペイン語、フランス語……それぞれの言語が持つ固有のリズムや構造を、Geminiに対してどのように命令し、抽出させているのか。
次回、「プロンプト設計編:config.yaml で実現する多言語プロンプト・インジェクション」。 ハードコーディングを一切排除し、YAMLファイル一つでアプリの「知能」をスケーラブルに拡張する、エンジニア必見のプロンプト設計思想を公開します。
お楽しみに!
- 土台(状態管理)が完成したことで、次は「どうやって多言語を解析するか」という中身の話へ。
- 次回予告:
config.yamlを使った多言語プロンプト設計。

