

In my previous post, I shared how my development came to a grinding halt following the deprecation of Gemini 1.5.
As of 2026, Gemini has fully transitioned to the Gemini 3 generation. Gemini 1.5 is officially DEPRECATED, and support is being phased out. Relying on a single API is a dangerous game—one day your code works perfectly, and the next, it “bites” you with a 429 Resource Exhausted error.
Instead of just fixing the error, I’ve decided to take a proactive leap: Implementing a Multi-Model Redundancy Strategy.
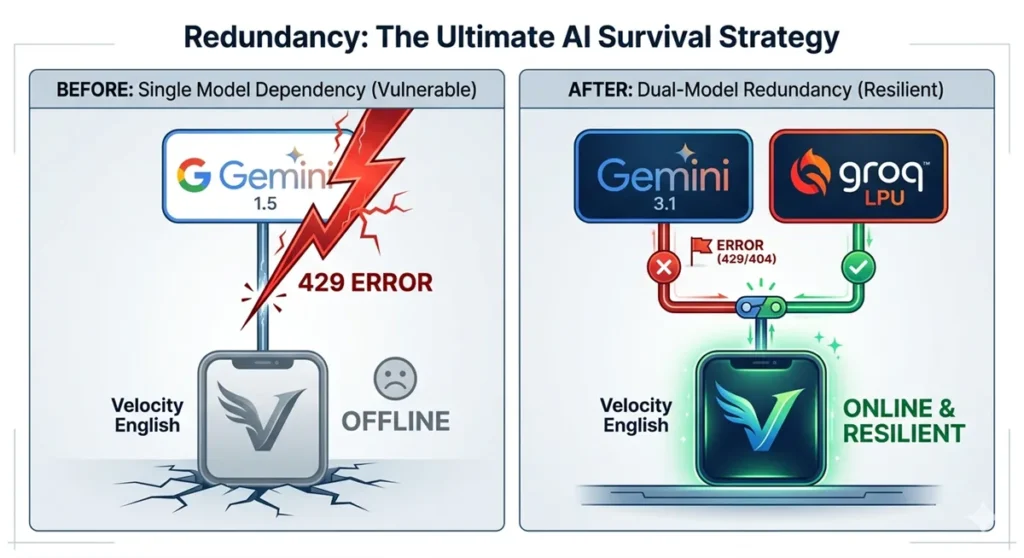
- Context: Moving away from single-API dependency due to Gemini 1.5 deprecation.
- Strategy: Hybrid “Quality (Gemini 3.1) x Speed (Groq)” architecture.
- Goal: Building a sustainable, vendor-independent system.
🛠️ Phase 2.5: The Road to Multi-Model Architecture
While multi-model support is becoming common, it brings a major headache: Inconsistent outputs. For my project, Velocity English, switching models might mean a “City Boy” accent suddenly turns into a “Texas Drawl.”
Despite this, here are three undeniable reasons to go multi-model:
1. Downtime is “Death” (Redundancy)
A redundancy-first mindset is the ultimate survival strategy for AI apps. If your primary provider (e.g., OpenAI or Google) goes down, showing a “Service Unavailable” screen is the worst-case scenario. A fallback system that switches to a comparable model is industry standard.
2. “Right Tool, Right Job” (Cost & Latency)
Running everything on a high-end model (like Gemini 3 Pro) kills your budget and slows down response times.
- Simple Classification/Summarization: Use lightning-fast, cheap models (e.g., Llama on Groq).
- Complex Reasoning/Final Output: Use high-intelligence models (e.g., Gemini 3 Pro).
3. Avoiding Vendor Lock-in
Designing code that allows for an immediate switch to another provider is a crucial business decision. Don’t let a single company’s policy change or price hike dictate your product’s fate.
🛠️ The 2026 Toolkit: 4 Candidates for Multi-Model Integration

For Phase 2.5, I evaluated APIs based on Speed, Intelligence, and Free Tier Generosity.
- Groq Cloud (API): The hottest choice among engineers right now.
- Pros: Insane inference speed. Free access to Llama 3/Mixtral.
- Use Case: Critical for apps like Velocity English where “feel” depends on response time.
- Hugging Face Inference API: The GitHub of AI.
- Pros: Access to 10,000+ open-source models.
- Use Case: Perfect for experimenting with the latest state-of-the-art models.
- OpenAI (GPT-4o mini): The industry standard.
- Pros: High stability and ecosystem support.
- Use Case: Learning the standard OpenAI-format API integration.
- Gemini (Google AI Studio): The cutting-edge brain.
- Pros: Superior multimodal capabilities and “Grounding with Google Search.”
- Use Case: When you need real-time web info or advanced voice/image processing.
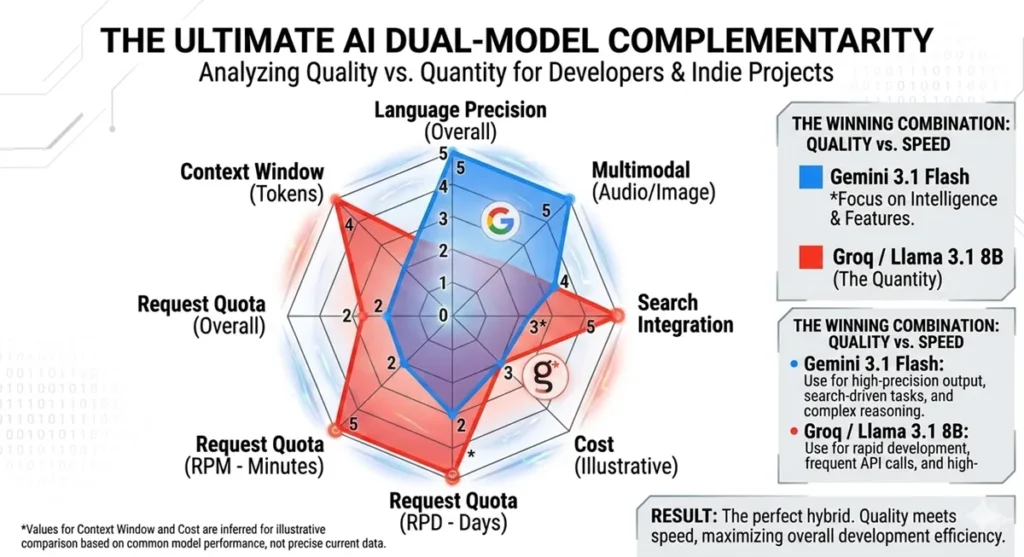
✒️ Why I Chose Gemini + Groq
In short: It’s the perfect synergy of “Elite Intelligence (Gemini)” and “Massive Throughput (Groq).”

- Gemini 3.1 Flash (Quality): Handles complex Japanese nuances and web-connected outputs.
- Groq / Llama 3.1 (Quantity): Handles the “Bakusoku” (High-speed) rapid-fire testing required during development with its high rate limits.
🏁 Toward Sustainable, Platform-Independent Development
The “baptism” of the Gemini 1.5 shutdown taught me a valuable lesson: resilience means being able to open a new door the moment one closes.
Next time, I’ll dive into the [Implementation Phase], sharing the actual Python code on how to integrate this “Dual-Model” system. Stay tuned!
