

前回の「【実録】Gemini API 429/404エラーと決別の記録」記事ではGemini1.5のサポート終了を受けて開発がストップしてしまいました。
このサポート状況を調べたところ、2026年現在、Geminiは 「Gemini 3」 世代に完全移行し、Gemini 1.5はサポート終了(DEPRECATED) となり、順次リタイアが進んでいる状態。
Gemini一本に依存しているようではだめだな・・・。「昨日まで機嫌よく動いていたコードが、突然牙を剥く」なんてことはよくあること。エラー対応「429 Resource Exhausted」は勉強になったが、開発速度が損なわれるのはいただけない。
ここはポジティブに考えて、APIを冗長構成にして使い分ける方針マルチモデル対応に舵を切ってみよう。
忙しい人の為の3行まとめ
- 背景: Gemini 1.5廃止に伴い、単一API依存の限界を痛感。
- 戦略: Gemini 3.1(質)× Groq(量)のハイブリッド構成へ移行。
- 結論: 特定のプラットフォームに依存しない「止まらないシステム」を構築。
🛠️ Phase 2.5:マルチモデル対応への道
世に出てるアプリではマルチモデルを搭載しているものもある。問題点としては、回答・生成内容に差が生じてしまうことだ。
この「生成内容に差が出る」という懸念は、商用アプリを開発するエンジニアが最も頭を抱えるポイントの一つでもある。
俺が今作っているVelocity Englishについて、例えばシティーボーイな英語なのに、別のモデルに切り替わったらテキサスな英語になったり、とざっくりと言えばこんな感じになってしまう。
そこで、そういった事情を考慮しても搭載すべき理由がある。
1. サービスの停止は「死」を意味するから(冗長化)
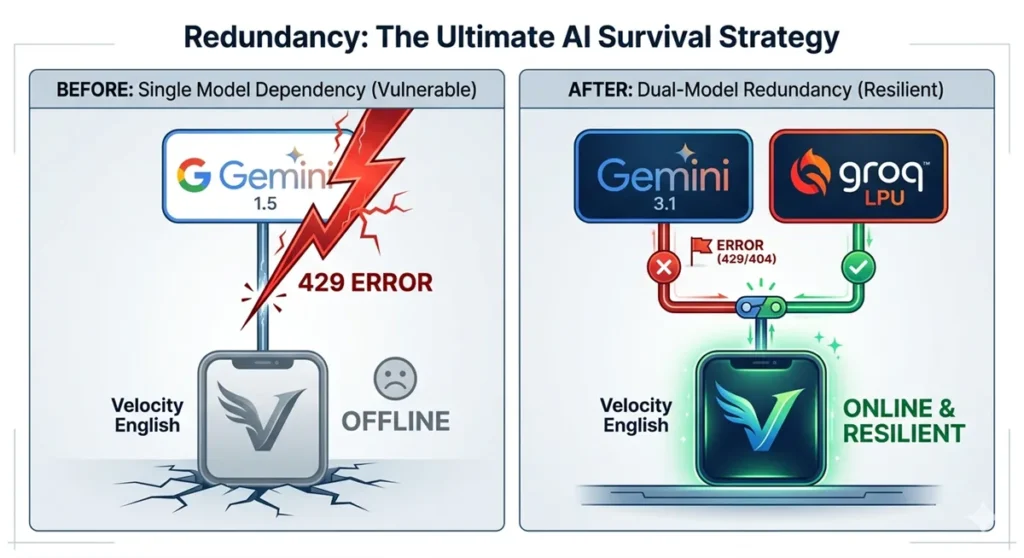
特定のAI(例:OpenAI)がサーバーダウンしたり、APIの障害を起こしたりした時、アプリが「現在使えません」となるのは最悪だ。 そのため、「メインが落ちたら、性能が近い別モデルに切り替える」というフォールバック(予備)としてのマルチモデルは、システム・アプリの世界においては常識。
2. 「適材適所」でコストと速度を最適化する
すべての処理を一番賢くて高いモデル(Gemini 3 Proなど)にやらせると、コストが爆上がりするし、返答も遅くなる。
- 簡単な分類や要約: 爆速で安いモデル(Groq上のLlamaなど)
- 複雑な思考や最終出力: 賢いモデル(Gemini 3 Proなど) このように、「1つのアプリの中で、機能ごとにモデルを使い分ける」**マルチモデル手法が一般的だ。
3. ベンダーロックインの回避
特定の会社(GoogleやMicrosoft)の規約変更や値上げに振り回されないよう、いつでも他社に乗り換えられるようにコードを設計しておく。これは経営判断として非常に重要。
🛠️ 2026年:マルチモデル対応をするにあたって候補は4つ

マルチモデル対応をするにあたって候補となるAPIは沢山ある。そこで「速い」、「賢い」、「豊富な無料枠」という観点で洗い出して以下の4つの候補が上がりました。
1. Groq Cloud (API)
今、エンジニアの間で一番アツいのがこれだ。
- 特徴: 爆速。とにかく返信が速い。Llama 3やMixtralといった超高性能なオープンソースモデルが無料で使える。
- 無料枠: 回数制限はあるけど、開発中のテストなら十分すぎるほど寛容だ。
- 用途: Velocity Englishみたいな「レスポンスの速さ」が命のアプリには最適といえる。
2. Hugging Face Inference API
AI界のGitHubこと「Hugging Face」が提供している。
- 特徴: 膨大な数のオープンソースモデル(数万種類!)をAPI経由で叩ける。
- 無料枠: 誰でも無料で使えるけど、モデルによってはたまに「スリープ中」で返信が遅れることがある。
- 用途: 「この最新モデル、ちょっと試してみたい」っていう実験場にぴったり。
3. OpenAI (GPT-4o mini)
意外かもしれないけど、OpenAIも特定の条件で無料枠(ティア)がある。
- 特徴: 業界標準の安定感。
- 無料枠: 以前の「無料クレジット」枠は厳しくなったけど、最近は特定のプロジェクトや利用状況に応じて低価格、あるいは期間限定の無料枠が設定されることもある。
- 用途: 業界標準のAPI構成(OpenAI形式)を学ぶために一度は触っておくべきだね。
慎重に検討を
4. Gemini (Google AI Studio)
Googleが誇る最新鋭モデル。現在は Gemini 3.1 Flash が開発のメインストリームだ。
- 特徴: 「圧倒的なマルチモーダル能力」と「Google検索連携」。 テキストだけでなく、音声や動画をそのまま理解する能力がズバ抜けている。さらに「Grounding with Google Search」を使えば、最新のネット情報を踏まえた回答が可能。
- 無料枠: Gemini 3.1 Flash なら 15 RPM / 1,500 RPD と、個人開発には十分な枠がある。ただし、Proモデル(3.1 Pro)は制限が厳しいので、開発はFlash、勝負どころはProという使い分けが定石。
- 用途: 「最新のニュースを取り入れたい」「音声合成(TTS)や音声認識をアプリに組み込みたい」といった、一歩進んだAI機能を実装したい時に最適。
✒GeminiとGroqを選定した理由
一言で言うと、「最高クラスの知能(Gemini)」と「圧倒的な手数(Groq)」を補完し合う、理想的な凸凹コンビだから。
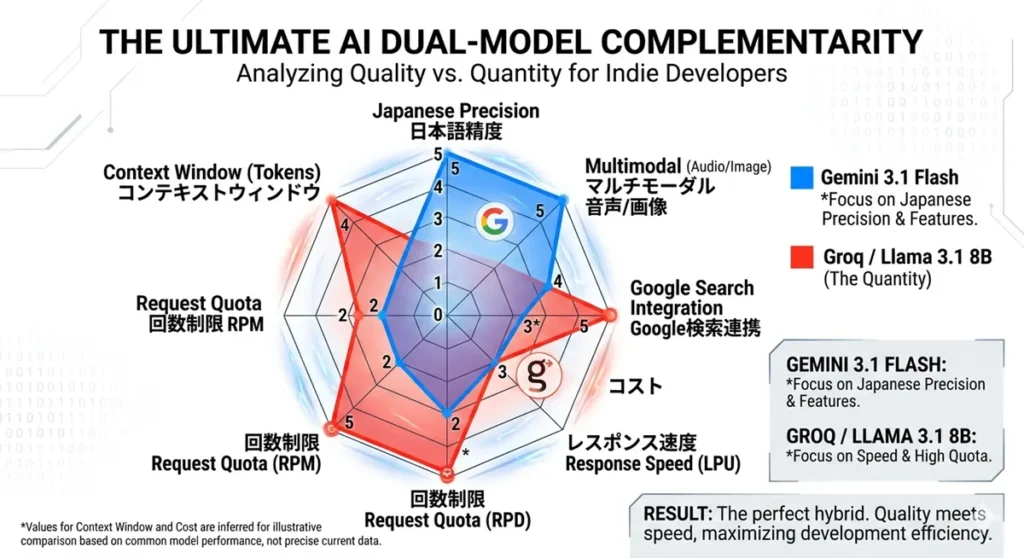
🚀 理由1:無料枠の「質」と「量」が完璧に噛み合っている
個人開発者にとって、API制限は最大の敵だ。この2つを組み合わせるとその隙がなくすことが出来る。
- Gemini 3.1 Flash(質): Google検索との連携や日本語の自然さがズバ抜けている。「本番の出力」や「複雑な日本語のニュアンス」を任せるのに最適。
- Groq / Llama 3.1(量): 1分間に30回、1日に14,400回という「実質無制限」に近い圧倒的な回転数。コードを1行直すごとにテストする「爆速開発」に欠かせない。
🛠️ 理由2:実装の「手間」が最小限で済む
エンジニアは「楽をすること」に命をかけている。この2つは、乗り換えのコストがめちゃくちゃ低い。
- OpenAI互換性: Groqは、世界標準である「OpenAI形式」の書き方で叩ける。
- ライブラリの安定性: 両方ともPythonライブラリが非常に優秀で、ドキュメントも豊富だ。一度「共通の接続パーツ」を作ってしまえば、中身を入れ替えるのは数行の変更で済む。
⚡ 理由3:「レスポンス速度」の緩急がつく
アプリの「触り心地」を決める要因の一つはレスポンスの速さだ。
- GroqのLPUエンジン: 返答が「一瞬」で返ってくる。今作っているVelocity Englishのような、テンポ良く学習を進めたいアプリの「骨組み」にはこの速さが武器になる。
- Geminiのマルチモーダル: 速さではGroqに譲るが、画像や音声を含めた「リッチな体験」を後から追加しやすい。
🏁 「特定のプラットフォームに依存しない、持続可能な開発を目指して
特定のAIモデルに依存するということは、そのモデルの機嫌(API制限やサポート終了)に自分のプロダクトの命運を預けるということ。
今回、Gemini 1.5の終了という「洗礼」を受けたことで、「一つの扉が閉まっても、別の扉を即座に開けられる構造」こそが、個人開発者が長く生き残ることだと学んだ。
だからこそ、多くのAIモデルを調べることにもつながったし、その中で頭脳のGeminiと手数のGroqという選択をすることができた。
これをもって、俺の『Velocity English』を始めるとしよう。
「回答の差」という課題はあるが、それはプロンプトの工夫やエンジニアリングでねじ伏せていけばいい。まずは止まらないシステムを作ること。話はそれからだ。
さて、戦略は決まった。 次回はいよいよ、Pythonを使ってこの「二刀流」を実際にどう組み込むのか、具体的なコードと共に解説する【実装編】をお届けする。


